成立于2012年的北京金山云網絡技術有限公司*(以下簡稱“金山云”)�����,是國內領先的云計算服務提供商,以業內領先的用戶體驗和服務端技術�����,為用戶提供國內領軍級云服務產品�。目前�,金山云擁有云服務器、海量云存儲�����、負載均衡���、云關系型數據庫等多項核心業務�����,幫助客戶實現動態配置資源��,應對業務的劇烈變化,提升業務的穩定性。現在����,金山云每天新增數據量達500T��,總存儲規模超過400PB,海量分布式存儲技術已達世界領先水平����。未來�����,金山云將持續加大投入,力爭成為全球領先的云計算服務商��。
面臨挑戰
• 平臺部署復雜度對效率產生影響:大數據時代的到來�,令企業用戶認識到利用大數據幫助企業進行經營決策的重要性,各企業紛紛著手部署自己的大數據分析平臺��。但平臺部署的復雜度及維護難度卻成為企業用戶大數據發展的路障�。
• 分析處理性能的要求提高:大數據處理分析的結果將對用戶的決策產生直接影響�����,因此����,數據處理過程需要更加實時�����、穩定和準確�,這些都對進行大數據分析處理的動力源平臺提出了更高的性能要求��。
• 降低企業的TCO壓力:企業的業務變動會帶來大數據處理資源需求的頻繁變動���,無論對于自建系統還是云平臺都會造成成本壓力���,同時也帶來資源浪費�����。
解決方案
• 可以快速部署、彈性擴展的金山云KMR產品:針對用戶需求,KMR提供多種節點配置���,可彈性增加或減少節點,應對用戶多變的業務需求;同時,分鐘級集群部署和擴容能力���,可以幫助用戶快速部署�。
• 成熟生態圈為平臺提供延展性���,降低運營成本:圍繞KMR���,金山云還提供云存儲�����、云主機、關系型數據庫等一系列服務����,為用戶提供延伸服務�����。同時,KMR通過與其他產品整合,也使用戶的運營成本更低,數據可靠性更高����。
• 英特爾®架構產品支持高性能云數據分析平臺:通過引入英特爾®至強®處理器E5家族�����、英特爾®固態盤以及英特爾®萬兆位以太網服務器適配器等產品,KMR產品在處理能力�、穩定性等多個性能指標上都擁有卓越表現�。
由英特爾®至強®處理器E5產品家族�����、英特爾®固態盤以及英特爾®萬兆位以太網服務器適配器支持的金山云KMR解決方案�����,以其高性能、易部署�、擴展性強和生態鏈完整的特性來協助企業進行大數據分析工作,為企業的經營和發展策略添磚加瓦���。
影響
• KMR的優異表現體現了英特爾技術對云平臺產品的良好支持:通過用戶實踐和綜合測評,KMR的優異表現都證明����,英特爾的產品和技術可以讓數據中心/云計算平臺在高性能�����、可擴展性等方面如虎添翼。
• 金山云良好的云生態建設思路為云平臺的發展提供實踐:金山云提供的多種云服務產品打造了成熟的云生態環境�����。KMR與這些服務進行組合��,形成端到端的數據分析處理解決方案����。這種一攬子方案的模式不僅獲得了用戶的好評��,也為未來云平臺的發展提供了良好實踐���。
大數據的價值逐漸凸顯���,大數據的分析處理成為用戶關注的焦點�。通過大數據處理與分析��,用戶可以獲取有益信息�����,輔助經營決策�����。大數據處理分析工作對平臺的計算��、存儲�����、網絡性能有著很高的要求。現在�����,利用Apache Hadoop*��、Apache Spark *以及先進的云平臺技術來執行大數據處理與分析已成為業界的重要選擇�����。Apache Hadoop*是一個處理、存儲和分析海量分布式���、非結構化數據的開源框架。它可以使用簡單的編程模型�,跨計算集群對大數據進行分布式處理�。Hadoop的重要模塊MapReduce*善于從海量數據中對用戶所關心的內容進行提取和分析���。Apache Spark*是另一種為大規模數據處理而設計的通用計算框架���,通過使用內存計算來提升性能����。
利用云平臺進行大數據處理時����,用戶面臨的重要挑戰是如何對平臺進行部署、管理與擴展,包括安裝和操作管理能力、動態分配多任務負載下數據處理的能力以及多數據整體分析的能力���。針對這一挑戰,金山云推出托管Hadoop Kingsoft Map Reduce,以下簡稱KMR�����,這是一種基于 Hadoop*�����、Spark* 等計算框架的集群托管服務��,可以方便用戶快速構建數據分析集群、處理海量數據����。同時也可配合金山云KS3����、KTS�、RDS等產品為用戶提供端到端的大數據解決方案。
完全托管�,集群分鐘級快速部署
過去��,企業通過自建平臺來進行計算、存儲�����、數據處理等工作����,這種方式會消耗大量資源在軟����、硬件維護上。例如����,部署一個典型的Hadoop平臺�,通常需要經歷業務評估���、設備選型采購、硬件上架調試�、操作系統和平臺軟件安裝調試等一系列復雜工作����,花費1-3個月的時間����。同時,企業在專業維護人員上的缺失也使自建平臺在安全性�����、系統穩定性等方面的表現不盡如人意���。因此����,很多企業都逐漸將目光轉移到云平臺上。
盡管如此���,向云平臺的轉移卻并不能完全消除用戶在部署上遇到的問題,面對不同的業務需求��,用戶仍需要耗費一定的資源去執行部署和維護的工作��。KMR的重要優勢,就是能最大程度地幫助用戶降低部署的復雜度和運維的工作量����。通過采用彈性計算服務(Kingsoft Elastic Compute,KEC)構建集群����,通常情況下只需幾分鐘即可自動完成部署工作����,用戶只需關心數據處理任務本身,而不需要關注硬件和底層系統的運維工作��。
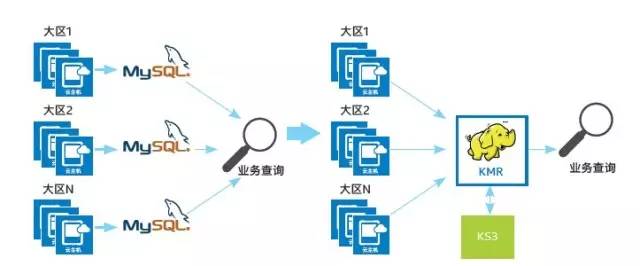
以KMR在游戲廠商的實際部署為例����,由于游戲行業具有極強的短期爆發能力,一款S級游戲短期內就需要開放數百組游戲服務器��,這些服務器每天會產生幾十甚至上百GB的日志需要集中存儲并滿足不定時查詢��。最初�,日志采用分區灌入My SQL數據庫并執行定期查詢���,然后匯總結果計算相關的KPI指標���。但運行一段時間后發現�����,數據存儲成本高��,系統可用性得不到保障,需要手動維護不同數據集之間的關系��,查詢效率低下且靈活性受限����。
在部署KMR之后��,所有的日志數據都通過KMR統一存儲��、統一處理,快速建立集群環境,并可根據游戲用戶規模在數分鐘內進行擴容/縮容。同時,利用金山云完善的云生態環境,數據可存儲在對象存儲KS3中����,使用KMR直接查詢����,除了節省了大量人力�����,提高了效率��,并大幅降低了存儲成本�����。據測算,存儲成本可節省75%以上。
圖一 部署KMR以應對游戲日志處理
性能優化�����,大數據分析即時響應
大數據分析處理的核心目的是為行為決策提供參考�,因此時效性是評價其分析平臺能力好壞的重要指標。在一些特殊場景中數據的處理分析速度帶來的影響更不容小覷����。
例如在醫療行業���,數據分析已迅速成為分析健康危險因素和改善病人護理的核心。各類病患的數據,包括臨床�����、病史����、用藥史以及DNA,需要依托于云計算才能夠被更快速����、更高效和更準確地進行分析����,幫助醫生對病患的病情進行診斷����,以對癥下藥從而達到最佳的治療效果。同時��,可以幫助醫院及醫生積累病例數據��,進行科研分析提煉��,并幫助新藥的開發。利用大數據分析,還能夠幫助醫療衛生機構對可能的疫情進行預測和監控����,進行全民健康管理��;KMR領先的大數據分析能力,可以良好應對醫院全面�、復雜��、多變的業務和科研場景,為臨床決策提供有力支持�����,提升醫院的運營效率��、提升醫療衛生系統對健康、疾控等方面的管理能力����。
在某醫院的部署實踐中����,醫院的總數據量已經達到280TB��,臨床數據中CDR(Clinical Document Repository)����,的數據庫記錄了10億條患者診療信息���。通過KMR的部署���,用戶可以以毫秒級的速度對信息進行查詢,并在極短的時間內獲得分析結果�。KMR強勁的性能表現得到了英特爾.至強.處理器E5系列���、英特爾.SSD以及英特爾.萬兆位以太網服務器適配器的支持�。英特爾.至強.處理器 E5-2600 v4基于14 納米處理技術構建��,提供每插槽高達22個內核/44 條線程和每插槽高達 55 MB 最新級別高速緩存(LLC)�,以提高性能�;同時,提供英特爾. 事務性同步擴展(英特爾. TSX)來提升并行工作負載性能�����。
同時����,英特爾固態盤以及英特爾萬兆位以太網服務器適配器的引入��,也令KMR性能表現卓越�����。適用PCIe* 的英特爾數據中心固態盤可以直接為英特爾至強處理器提供極致的數據吞吐量,在KMR中采用的高性能英特爾®以太網聚合網絡適配器X520-SR2,針對苛刻的數據中心/云環境提供了高度的靈活性以及可擴展性。
在硬件產品以外���,英特爾在各類大數據分析軟件庫上的貢獻也為金山云的性能加速提供了動力。例如英特爾高性能數據分析加速庫(Intel® Data Analy ticsAcceleration Library,以下簡稱Intel®DA AL)��,包含了基于英特爾平臺優化的常用機器學習算法庫(如K-Means���,LR�,PC A等)。在英特爾工程師的協助下���,金山云完成了Intel® DAAL庫的評測。DAALK-Means算法對應傳統的Spark ML-Lib算法有近4.6倍性能提升���。
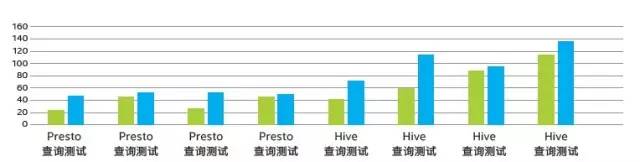
通過一項對2億4千萬條模擬樣本數據的測試表明,金山云在數據處理分析性能上優于競品:
圖二 金山云KMR模擬樣本數據對比測試
經驗
• 用戶選擇云服務來執行大數據處理分析工作的最大初衷是獲得靈活���、高效、易部署�、易擴展的特性以及TCO的降低�����,因此彈性可伸縮的云服務最受用戶青睞。
• 大數據分析并不僅僅只是對數據進行處理和分析那么簡單��,相關的存儲�、傳輸等功能同樣重要�����。完整的生態鏈有助于基于云的大數據分析平臺更長遠和健康的發展��。
• 實踐證明,英特爾.至強.處理器E5產品家族�、英特爾.固態盤以及英特爾.萬兆位以太網服務器適配器有助于KMR性能提升�����,獲得更好用戶體驗,同時��,英特爾不斷引領著各項大數據開源技術正為大數據處理分析技術的發展提高源源不斷的動力�。
生態豐富,彈性服務有效降低TCO。
用戶數據從產生到最終體現價值�,包含收集����、存儲���、分析處理和消費等多個環節�,每個環節又有多種多樣的需求。除了KMR以外,大數據的處理與分析還需要多種云服務能力的配合?����;诮鹕皆曝S富的生態環境和良好的開放性�,KMR不僅提供了豐富的開源生態組件,還可以和其他云服務產品以及第三方的解決方案無縫集成����,共同構建端到端的大數據生態��。
以存儲為例�����,KMR提供了金山云KS3 (標準存儲服務)訪問接口����。在進行數據處理時,通過內部高速網絡直接訪問KS3的同時���,也可將原始數據將統一匯總到這里。KMR集群中運行的 Map Reduce�����、Spark等作業就可以直接調用KS3中存儲的數據進行計算���,并把結果寫回到KS3���。KS3提供了較低的使用成本和極高的數據可靠性����,保證了在集群釋放時仍然可以持久地存儲原始數據和計算結果。
圖三 KMR支持豐富的開源生態組件
同時�,KMR對大量開源生態組件都具有較好支持�����,除集成了最基礎的Hadoop組件外,還集成了Spark, Hbase��,Storm, Kafka等生態組件�����,以及Ambari, Ganglia等集群監控管理工具��,可以幫助用戶輕松構建復雜的大數據分析系統�����,滿足批量計算���、流式處理����、消息隊列����、交互式查詢、NoSQL等多種業務場景的需求�����。
KMR集群的靈活配置也有助于用戶合理調整工作集群數量����。通常,KMR集群由主節點(Master Node)和若干核心節點(Core Node)及任務節點(Task Node)組成���。KMR提供了多種節點配置,用戶可在需要時動態增加或者減少節點數量�。這種強大的擴展能力和彈性伸縮能力����,消除了Hadoop安裝部署成本和管理復雜性���,讓用戶可以更加專注數據分析處理本身
新興的電商網站往往擁有幾十個大類�、數百萬種商品,每天的增量數據高達數TB,遇到各種促銷期間�,IT資源的需求更會陡增�。這種潮汐型的需求���,如果采用自建系統的方式�����,將耗費大量資源在備用機上����,造成大量資源浪費�。
采用KMR之后,電商網站通過直連專線的方式連接金山云數據中心����,由KMR服務快速創建Storm和Kafka集群���,搭建實時數據處理系統��,數據處理結果寫入MongoDB服務;由KS3服務應對海量存儲需求�����,獲得高性價比��,高可靠性存儲服務�。通過與金山云完整生態系統的融合�����,電商網站促銷期間IT系統的壓力得到了有效的緩解�����,系統維護工作和資源擁有成本(TCO)大幅減少����,資源也可以根據業務需求進行靈活的調整和配置。
展望未來,新技術助推更優服務
隨著虛擬化技術、超融合解決方案�、軟件定義數據中心等云平臺相關技術的不斷發展����,金山云將繼續優化KMR產品�,為用戶提供優質的云服務方案。作為大數據分析領域領跑者的英特爾,也將繼續助理金山云完善KMR產品,為用戶提供更優質服務。
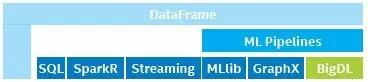
現在���,英特爾開源了基于Apache Spark *的分布式深度學習庫BigDL*,可以直接運行在金山云一類的Hadoop/Spark集群上�����,并允許用戶編寫標準的Spark程序來進行深度學習的訓練與預測����。實踐表明,BigDL的特性表現在:
• 深度學習能力:與Torch一樣�����,BigDL全面支持Tensor數值計算和高層次神經網絡深度學習���;同時��,用戶還可以使用BigDL加載預先經過培訓的Caffe或Torch模型到Spark程序中��。
• 高性能:BigDL在每個Spark 任務內使用英特爾® MKL和多線程的編程。因此它比開源Caffe�����、Torch或單節點英特爾至強處理器上的TensorFlow性能都有數量級的提升���。
• 高效擴展:通過實施Spark上的同步 SGD和all-reduce通信�����,BigDL可有效進行橫向擴展����,以匹配“大數據規模”的能力執行數據分析�����。
圖四 基于Apache Spark *的BigDL*架構
未來�����,通過提供類似于BigDL的先進技術,英特爾可以幫助金山云的用戶在KMR及相關平臺上獲得數據存儲��、預處理���、分析和深度學習等一站式服務�,獲得更強勁的大數據分析和處理能力。
文章摘自英特爾精英匯
歡迎聯系寶通集團咨詢英特爾相關產品信息
寶通集團聯系方式
咨詢熱線:400-830-0107
寶通官網:www.btibt.com
客戶垂詢郵箱:Customer@ex-channel.com
客戶垂詢QQ:1305742380
地址:深圳市福田區深南大道1006號國際創新中心C座11樓
郵編:518026
 當前位置:
當前位置:





 粵公網安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計算 |
粵公網安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計算 |