 當(dāng)前位置:
當(dāng)前位置:服務(wù)熱線
0755-83647532

發(fā)表日期:2017-03-02 文章編輯:管理員 閱讀次數(shù):
進(jìn)入21世紀(jì)后,計(jì)算機(jī)的體系結(jié)構(gòu)并沒有停止前進(jìn)的步伐,尤其是在處理器領(lǐng)域所取得的技術(shù)突破奠定了包括云計(jì)算、大數(shù)據(jù),以及近幾年炙手可熱的機(jī)器學(xué)習(xí)的基礎(chǔ),在軟件定義時(shí)代來臨之后,硬件的作用卻絲毫沒有降低,反而越發(fā)顯得重要。
隨著制造工藝越來越接近極限,計(jì)算場景化的不斷豐富,在通用計(jì)算場景下,可編程能力顯的極為重要,在專用計(jì)算場景下,大規(guī)模并行與低延遲又變的不可或缺,面對(duì)這一前所未有的復(fù)雜局面,比較可行的辦法是軟件與硬件的高度協(xié)同,通過對(duì)硬件層面能力的控制權(quán)直接暴露給操作系統(tǒng),乃至運(yùn)行于用戶態(tài)的Application來滿足可編程與性能等不同場景的要求,這種做法比比皆是,其中之一就是NUMA(None Uniform Memory Acess)技術(shù),接下來我們深入其中看一看這項(xiàng)技術(shù)的來龍去脈以及如何影響到云平臺(tái)的。
術(shù)語
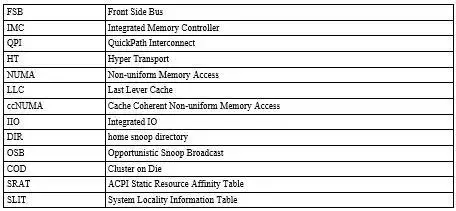
NUMA 結(jié)構(gòu)簡介
隨著處理器的工作頻率的提高和由于一些材料工藝限制導(dǎo)致處理器的發(fā)展朝向多core多socket帶來一個(gè)明顯問題- 我們所熟知的FSB結(jié)構(gòu)在多個(gè)性能強(qiáng)勁的處理器面前會(huì)成為競爭點(diǎn)。為了解決這個(gè)問題,AMD于2003年在第一代Athlon64位處理器中首次采納了HT(Hyper Transport)設(shè)計(jì),并提出把內(nèi)存控制器由北橋挪到了處理器管芯中的設(shè)計(jì),隨后Intel借鑒并于2004年提出了類似的設(shè)計(jì),稱之為QPI(QuikPath InterConnection),但是在Xeon中采用這項(xiàng)技術(shù)已經(jīng)是2009年的Nehalem了,HT與QPI都采用的point-to-point interconnect技術(shù),來保證處理器間的高速通信。結(jié)果如下圖所示的:

每個(gè)處理器都有自己的IMC,連接到本地內(nèi)存。這樣在增加和提高處理器數(shù)量和工作頻率的時(shí)候,本地內(nèi)存的訪問效率也可得到保證。 這也就是我們要討論的NUMA系統(tǒng)。每個(gè)處理器和它本地的內(nèi)存(加上有可能存在的處理器集成IO)構(gòu)成一個(gè)NUMA節(jié)點(diǎn)。再以Intel為例,結(jié)合CBox和HA間的snooping protocal,共享的LLC的一致性也得以保證。事實(shí)上X86的NUMA系統(tǒng)也都是ccNUMA。
由于目前在用的Intel機(jī)器基本上都是2個(gè)NUMA節(jié)點(diǎn)的結(jié)構(gòu),所以經(jīng)常在資料中提到的NUMA節(jié)點(diǎn)間的距離問題實(shí)際往往是不用考慮的。最新的Intel® Xeon® Processor E7-8860 v4和Intel® Xeon® Processor E5-4610 v4以上的CPU才支持8顆和4顆的系統(tǒng)配置,而服務(wù)器廠商出于成本考慮也會(huì)慎重考慮采用這樣的配置。即使在多顆CPU的配置下,不同NUMA節(jié)點(diǎn)之間的距離問題在QPI的配備下也無須擔(dān)心了,因?yàn)樗峁┤我鈨蓚€(gè)處理器的點(diǎn)對(duì)點(diǎn)的直接通信。 下圖較完整展示一個(gè)中端的系統(tǒng),雙Intel 2630 v4 CPU,10 cores (20 HT threads),4 memory channels,2 QPI Links,PCIe 40 Lanes Max。

從中可以清晰的看到,CPU0要訪問遠(yuǎn)程CPU1節(jié)點(diǎn)的內(nèi)存是需要經(jīng)過QPI,因此產(chǎn)生額外的latency。QPI的速率越快,這個(gè)latency就越小,然而此處理器的QPI速率是8 GT/s,換算后是要比這個(gè)系統(tǒng)所支持的最低的1600 MHz DDR4的內(nèi)存的訪問頻率慢的。訪問遠(yuǎn)程內(nèi)存即便有LLC的命中, 系統(tǒng)帶著Home Snoop with DIR + OSB的支持,也是要產(chǎn)生額外的開銷的。同樣道理,NUMA節(jié)點(diǎn)里所集成的IIO遠(yuǎn)程訪問是也有額外的latency。對(duì)于這個(gè)系統(tǒng)來說就是訪問遠(yuǎn)程的集成PICe也要經(jīng)過處理器間的QPI。事實(shí)上Intel的COD技術(shù)引入后,因?yàn)樗鼏⒂煤髸?huì)在一個(gè)處理器上劃分兩個(gè)NUMA節(jié)點(diǎn)來提高每個(gè)節(jié)點(diǎn)內(nèi)Ring Bus的帶寬進(jìn)而提高本地LLC在多核下的訪問速度,本地LLC訪問性能得到提升,遠(yuǎn)程的LLC的訪問卻未有提升。 并且需要軟件開發(fā)人員的注意的是,與絕大多數(shù)常見的NUMA系統(tǒng)不同,這時(shí)在同一socket上由COD邏輯劃分的NUMA節(jié)點(diǎn)與其它socket上的NUMA節(jié)點(diǎn)的距離是不同的,這可以在SRAT和SLIT中讀到具體信息。
當(dāng)然,免得麻煩,用戶可以簡單粗暴的選擇隱藏NUMA,啟用BIOS的Node Interleaving項(xiàng)去提供interleaved memory structure 影射所有節(jié)點(diǎn)的內(nèi)存, 不過這樣會(huì)產(chǎn)生粗略估計(jì)一半內(nèi)存訪問落到的實(shí)際遠(yuǎn)程內(nèi)存,系統(tǒng)無法發(fā)揮出最優(yōu)性能。
討論過NUMA結(jié)構(gòu)下系統(tǒng)性能提升和所須要避免的一些使用方式,接下來的兩個(gè)章節(jié)分別探討Linux以及基于Linux的云計(jì)算平臺(tái)OpenStack提供怎樣的機(jī)制讓我們更有效的使用NUMA結(jié)構(gòu)系統(tǒng)。
NUMA in Linux
對(duì)于NUMA系統(tǒng)來說,Linux會(huì)為每一個(gè)NUMA節(jié)點(diǎn)創(chuàng)建一套內(nèi)存管理對(duì)象的實(shí)例,每個(gè)節(jié)點(diǎn)包含DMA, DMA32, NORMAL等Zone。當(dāng)某個(gè)節(jié)點(diǎn)下的某個(gè)Zone無法滿足內(nèi)存分配請(qǐng)求時(shí),系統(tǒng)會(huì)咨詢zonelist進(jìn)而決定后備Zone的選擇順序。當(dāng)本地Zone NORMAL內(nèi)存不足時(shí),黙認(rèn)順序是從本地的Zone DMA32和DMA嘗試,然后再嘗試其它的節(jié)點(diǎn)。此順序可以由numa_zonelist_order參數(shù)更改,比如先去嘗試遠(yuǎn)程節(jié)點(diǎn)的Zone NORMAL以節(jié)省比較稀缺的Zone DMA32和DMA內(nèi)存(當(dāng)然,非黙認(rèn)NUMA policy有可能偏好遠(yuǎn)程節(jié)點(diǎn))。
NUMA Policy
Linux memory policy用來指定在NUMA系統(tǒng)下kernel分配內(nèi)存時(shí)具體從哪個(gè)節(jié)點(diǎn)獲取(Interrupt Context下不受policy限制 ,詳見alternate_node_alloc 和alloc_pages_current)。系統(tǒng)的黙認(rèn)policy為優(yōu)選當(dāng)前節(jié)點(diǎn)。不過在系統(tǒng)啟動(dòng)階段用的是interleave mode分配內(nèi)存,以避免過載啟動(dòng)節(jié)點(diǎn),同時(shí)也因?yàn)橄到y(tǒng)也無法預(yù)測(cè)運(yùn)行時(shí)那個(gè)節(jié)點(diǎn)的內(nèi)存訪問會(huì)更多。Memory policy可以作用于task和VMA上。作用于task時(shí)可以限制對(duì)于當(dāng)前task的所有內(nèi)存分配,并且會(huì)被child task繼承。VMA policy用來限制一個(gè)vm area的內(nèi)存分配。此時(shí)需額外注意,它只作用于anonymous pages(詳見alloc_pages_vma)并且被使用同一個(gè)地址空間的task共享。VMA policy優(yōu)先應(yīng)用于task policy。
Linux memory policy 支持四種不同的模式– DEFAULT,BIND,PREFERRED,和INTERLEAVED。Default意味著用下級(jí)備選policy(系統(tǒng)的黙認(rèn)policy為最后選擇),BIND強(qiáng)制內(nèi)存分配必須在指定節(jié)點(diǎn)上完成,PREFERRED模式在內(nèi)存分配時(shí)會(huì)優(yōu)先指定的節(jié)點(diǎn),失敗時(shí)會(huì)從zonelist備選,INTERLEAVED會(huì)使內(nèi)存分配依次(VMA的page offset或task的node counter)在所選的節(jié)點(diǎn)上進(jìn)行。
mbind和set_mempolicy系統(tǒng)呼叫用來更改當(dāng)前task和task地址空間里的VMA的policy。mbind更改VMA policy黙情況下只對(duì)之后分配的內(nèi)存有效,不過可以通過move或move_all 標(biāo)旗來強(qiáng)制移動(dòng)已分配的頁面。set_mempolicy更改task policy后,之前不符合此policy的頁面會(huì)逐步被NUMA Balancing挪到指點(diǎn)的節(jié)點(diǎn)。
NUMA Balancing
Automatic NUMA balancing可以將task遷移到它大量訪問內(nèi)存的節(jié)點(diǎn)上,同時(shí)將task錯(cuò)誤放置的內(nèi)存頁在晚些時(shí)候這個(gè)頁面被訪問到時(shí)按照policy的指示移動(dòng)(當(dāng)用戶改變內(nèi)存policy)。這主要是依賴內(nèi)核中的task_numa_work和do_numa_page兩段代碼。前者會(huì)被時(shí)鐘中斷處理加到task work上,然后在返回用戶態(tài)前(評(píng)估signal之前)運(yùn)行,用來去掉此task的內(nèi)存區(qū)的頁表(數(shù)量由numa_balancing_scan_size決定)PRESENT位并且用一個(gè)預(yù)留位來標(biāo)示此頁即將產(chǎn)生的Page Fault為NUMA Page Fault。它發(fā)生的頻率可以由numa_balancing_scan_period等參數(shù)調(diào)整。后者在Page Fault產(chǎn)生時(shí)用來處理NUMA Page Fault,來真正移動(dòng)不符合內(nèi)存policy的頁面。遷移task也是在此時(shí)跟據(jù)遠(yuǎn)程內(nèi)存訪的統(tǒng)計(jì)來進(jìn)行的。在無需挪動(dòng)頁面時(shí)此種Page Fault的開銷很小,只須將頁表的PRESENT位加上。用戶也可以主動(dòng)手工移動(dòng)內(nèi)存頁面到其它NUMA節(jié)點(diǎn),move_pages和migrate_pages兩個(gè)系統(tǒng)呼叫提供了這樣的功能。這里特別提及一下migrate_pages系統(tǒng)呼叫,與大多其它NUMA相關(guān)的系統(tǒng)呼叫不同,此呼叫可以用來移動(dòng)其它task(不局限于當(dāng)前task)的內(nèi)存頁面到不同的NUMA節(jié)點(diǎn)上,這也使用戶態(tài)下直接調(diào)整不同NUMA節(jié)點(diǎn)內(nèi)存使用的工具可以實(shí)現(xiàn), 比如migratepages工具。
cpuset
cgroup的cputset可以用來限定一個(gè)task可以在哪(幾)個(gè)CPU上運(yùn)行,以及它可以在哪些節(jié)點(diǎn)上獲取內(nèi)存。sched_setaffinity,mbind和set_mempolicy的行為也都是要受到cpuset的限制,也可理解為cpuset有著更高的優(yōu)先級(jí)。一個(gè)cpuset關(guān)連一組CPU和內(nèi)存節(jié)點(diǎn),系統(tǒng)中每個(gè)task都要搭載到一個(gè)cputset。黙認(rèn)情況下為root cpuset,此時(shí)充許使用所有的CPU和內(nèi)存節(jié)點(diǎn)。通過cpuset具體屬性的調(diào)整可以實(shí)現(xiàn)很多具體的需求。比如創(chuàng)建一個(gè)大的mem_exclusive cpuset去限制(hardwall)某些task在內(nèi)核態(tài)下的內(nèi)存分配只能在某些節(jié)點(diǎn)上,同時(shí)為每(幾)個(gè)task創(chuàng)建子cpuset來限定這些task在用戶態(tài)下可分配的內(nèi)存,這樣這些task可以在預(yù)定的節(jié)節(jié)上共享page cache等內(nèi)核數(shù)據(jù),同時(shí)每(幾)個(gè)task又可定義在用戶態(tài)下自己可使用的資源。
NUMA profile
有關(guān)不同NUMA節(jié)點(diǎn)內(nèi)存使用的信息可以在/sys/devices/system/node/nodeX 下的meminfo中得到, 同目錄下的numastat中可以得到在內(nèi)存分配過程中優(yōu)選節(jié)點(diǎn)備選節(jié)點(diǎn)的頁分配量,使用numastat工具還可以方便的獲得指定task的這些信息。更細(xì)粒度的信息采集需要用perf來直接收集有關(guān)NUMA的硬件事件,比如遠(yuǎn)程節(jié)點(diǎn)LLC的命中和遠(yuǎn)和內(nèi)存的訪問信息。具體的可收集事件不同的微架構(gòu)有所不同,需要參考Intel提供的文檔。
NUMA virtualization support
Libvirt/Qemu是在Linux下常見的虛似化方案,也是OpenStack的主要選擇。Libvirt在定義虛似機(jī)時(shí)充許用戶指定Qemu虛似機(jī)進(jìn)程的memory policy和虛似機(jī)及其vcpu綁定的物理cpu。在虛似機(jī)運(yùn)行時(shí)也可以通過命令更改虛似機(jī)及其vcpu的綁定,但memory policy在運(yùn)行時(shí)是無法改變的,因?yàn)楦膍emory policy的系統(tǒng)呼叫只可以作用由當(dāng)前task,Libvirt需要更改memory policy然后讓虛擬機(jī)進(jìn)程(子進(jìn)程)繼承。虛擬機(jī)及其vcpu的綁定不受此限制,因?yàn)榻壎ㄊ莄group和sched_setaffinity支持的,而它們不受此限制。Qemu也支持將物理機(jī)的NUMA拓補(bǔ)結(jié)構(gòu)“直通”給虛擬機(jī)。
-object memory-backend-ram,size=1024M,policy=bind,prealloc=on,host-nodes=0,id=ram-node0
-numa node,nodeid=0,cpus=0-1,memdev=ram-node0
-object memory-backend- ram,size=1024M,policy=bind,prealloc=on,host-nodes=1,id=ram-node1
-numa node,nodeid=1,cpus=2-3,memdev=ram-node1
如上所示,顯示的定義兩個(gè)memory backend, 通過bind memory policy去將這兩個(gè)VMA(Qemu為每個(gè)memory backend創(chuàng)建一個(gè)anonymous VMA)分別綁定到兩個(gè)不同的host NUMA節(jié)點(diǎn)上。
NUMA in OpenStack
OpenStack在Juno和Kilo以后分別加入了虛擬機(jī)NUMA節(jié)點(diǎn)布署拓補(bǔ)與vCPU綁定功能 。接下來章節(jié)我們一起看下這兩個(gè)NUMA相關(guān)的功能。
虛擬機(jī)NUMA節(jié)點(diǎn)布署拓補(bǔ)
此功能是通過flavor的extra specs (numa_nodes , numa_cpus , 和numa_mem )提供給用戶的。當(dāng)虛擬機(jī)的vCPU上內(nèi)存要求很高, 超出了物理機(jī)單個(gè)NUMA節(jié)點(diǎn)可提供的數(shù)目時(shí),或是某些情況當(dāng)虛擬機(jī)里的任務(wù)在多核上都產(chǎn)生極大的內(nèi)存訪問量使單個(gè)節(jié)點(diǎn)的內(nèi)存帶寬(甚至是訪問LLC對(duì)Ring Bus竟?fàn)?壓力過大,此功能可以用來顯示的指定虛擬機(jī)如何NUMA利用物理機(jī)上多個(gè)NUMA節(jié)點(diǎn)。下面的示例是將vCPU 0,1與2,3分別綁定到NUMA節(jié)點(diǎn)0與1上,同時(shí)要求1024與2048兆內(nèi)存分別在節(jié)點(diǎn)0與1上分配。
hw:numa_nodes=2
hw:numa_cpus.0=0,1
hw:numa_cpus.1=2,3
hw:numa_mem.0=1024
hw:numa_mem.1=2048
vCPU綁定
通過flavor的cpu_policy選項(xiàng)(設(shè)置為dedicated)也可以將虛擬機(jī)的vCPU具體綁定到物理機(jī)的某個(gè)core上,來滿足接有實(shí)時(shí)性較高的虛擬機(jī)任務(wù)的需求。配合內(nèi)核的isolcpus啟動(dòng)參數(shù)去把一些cpu放到isolated sched domain預(yù)留起來,以避免其它用戶態(tài)進(jìn)程被平衡調(diào)度過來,由此保證vcpu不被搶占。
References
1. An Introduction to the Intel ®QuickPath Interconnect January 2009
2. Intel ® Xeon ® Processor E5 v4 Product Family Datasheet Volume 2: Registers June 2016
3. Iakovos Panourgias - “NUMA effects on multicore, multi socket systems”, 9/9/2011
4. Frank Denneman - “NUMA Deep Dive Part 2: System Architecture” - http://frankdenneman.nl/2016/07/08/numa-deep-dive-part-2-system-architecture/
6. Linux Memory Policy - https://www.kernel.org/doc/Documentation/vm/numa_memory_policy.txt
7. joemario - “C2C - False Sharing Detection in Linux Perf” - https://joemario.github.io/blog/2016/09/01/c2c-blog/
7. CPU topologies - http://docs.openstack.org/admin-guide/compute-cpu-topologies.html
8. Steve Gordon - “Driving in the Fast Lane – CPU Pinning and NUMA Topology Awareness in OpenStack Compute” - http://redhatstackblog.redhat.com/2015/05/05/cpu-pinning-and-numa- topology-awareness-in-openstack-compute/
文章摘自英特爾精英匯
歡迎聯(lián)系寶通集團(tuán)咨詢英特爾產(chǎn)品信息
寶通集團(tuán)聯(lián)系方式
咨詢熱線:400-830-0107
寶通官網(wǎng):www.btibt.com
客戶垂詢郵箱:Customer@ex-channel.com
客戶垂詢QQ:1305742380
地址:深圳市福田區(qū)深南大道1006號(hào)國際創(chuàng)新中心C座11樓
郵編:518026


 粵公網(wǎng)安備 44030402001885號(hào)
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計(jì)算 |
粵公網(wǎng)安備 44030402001885號(hào)
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計(jì)算 |